
An Unpretentious Guide to Group A
Can a blind-data look tell us who’s getting out of this group?

Hi friend,
With the kick-off of the World Cup fast approaching (in a couple of hours), I must confess something.
As an Arsenal fan who has barely had time to catch his breath, I somehow did not realise the World Cup was starting today.
Honestly, I did not have much time to prepare.
So instead of watching ten preview podcasts, reading every tactical thread on Twitter, and pretending I had watched all of Czechia’s qualifiers, I did what any normal person would do.
I opened my laptop, pulled some Wyscout data, spent two hours cleaning it, and decided to create this unpretentious guide to Group A (Mexico, South Africa, South Korea and Czechia).
My purpose is twofold.
First, I want to see which players we should watch out for, based solely on national-team form and only according to the data.
Second, I want to come back once the games are played and see whether this blind-data approach actually pointed us somewhere useful.
The approach
I focus only on the players selected for the World Cup and only on their performances for their senior national teams.
More specifically, I look at matches played since 7 September 2023, which I define as the start of the World Cup qualification cycle. The hosts, of course, did not play qualifiers, so for them I include their other senior national-team games, including friendlies.
For each broad position group — goalkeeper, central defender, wing-back/full-back, defensive midfielder, central midfielder, attacking midfielder/wide attacker, and striker/link-up forward — I use a set of metrics to create player indexes (you may find the methodology here).
Then I use z-scores to compare the players.
If you are new to this, a z-score is just a way of saying how far a player is from the average player in the sample.
In plain English:
If a player has a z-score of 1.5, it means he is 1.5 standard deviations above the average for the players considered.
Which is the technical way of saying:
This guy stands out. A lot.
And yes, I know this methodology is not perfect.
Ideally, you would compare players who are playing in the same league, under similar conditions, against broadly similar opposition. Here, we are comparing players from four national teams who played in different parts of the world, in different qualification routes, against different opponents.
So, no, this is not a definitive ranking of player quality.
But that is not really the point.
The point is to compare the players in this group before I have watched most of them properly, using only the data available from their national-team performances.
It is a Substack post, not an academic paper.
My pub, my rules.
Let’s get into it.
1 — Best Goalkeepers
Here are the Group A goalkeepers ranked.
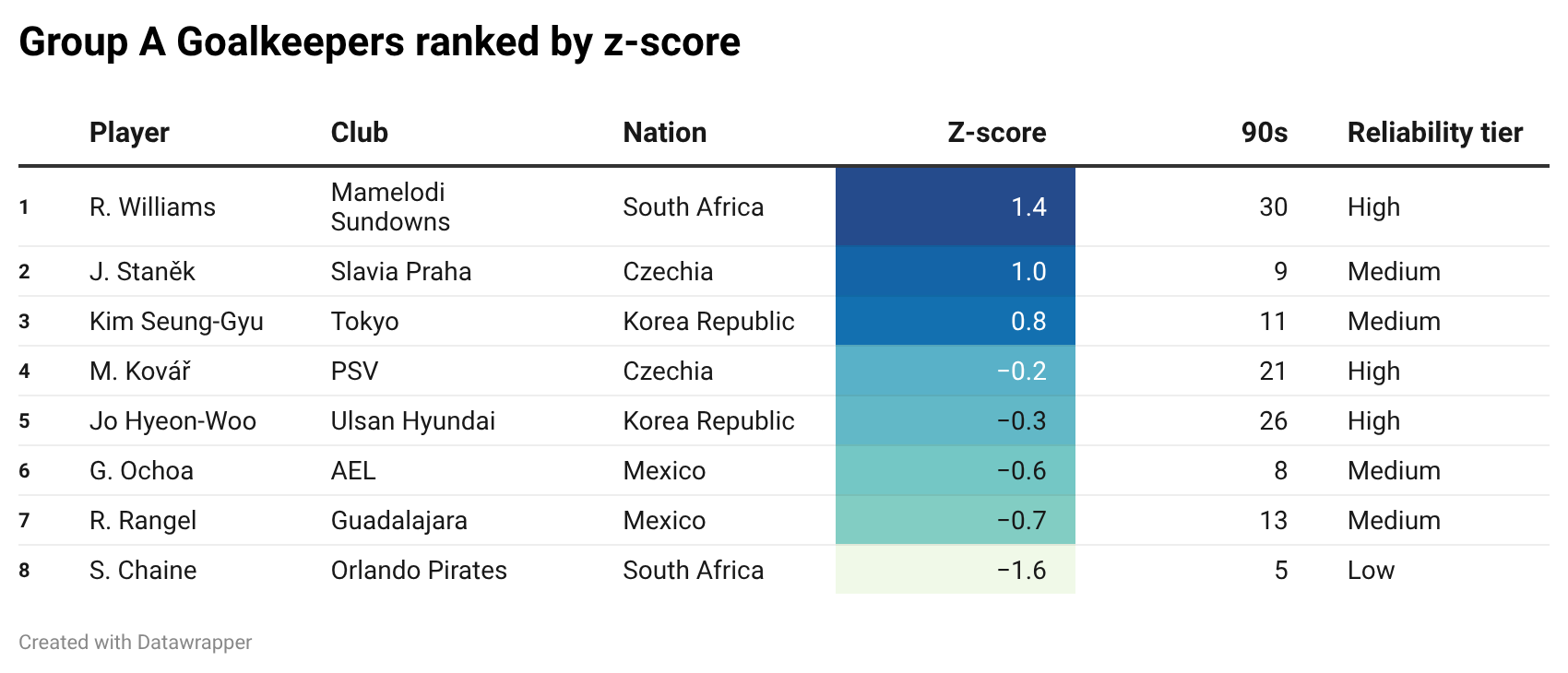
Ronwen Williams — the first (but not the only) player in this exercise I had to Google — tops the table with a z-score of 1.4. In plain English: among this group of keepers, the South African is the clear standout. He also comes with a solid sample: roughly 30 full 90s.
Second comes Czechia’s Jindřich Staněk, with a z-score of 1. That puts him about one standard deviation above the average keeper in this group. The sample is smaller, so I would be a little more careful here. But with Czechia’s other keeper sitting in negative territory, my data-only guess is that Staněk starts between the posts.
Third is Korea Republic’s Kim Seung-gyu, with a z-score of 0.8. That is (also) very solid. As a rule of thumb, once a player is above 0.5, he is already meaningfully above the group average.
So, overall, the top of the goalkeeper table is not especially chaotic. Williams leads, Staněk and Kim are comfortably positive, and all three look like credible tournament keepers on the data.
Then we get to Mexico’s eternal World Cup character: Guillermo Ochoa.
He comes in at -0.55, which means he was roughly half a standard deviation below the Group A goalkeeper average. Could he still pull off another World Cup resurrection and justify the memes one more time? Maybe.
But from a blind-data point of view, I’ll pass on this one.
2 — Best central defenders
When it comes to central defenders, there is one clear outlier: Kim Min-jae.
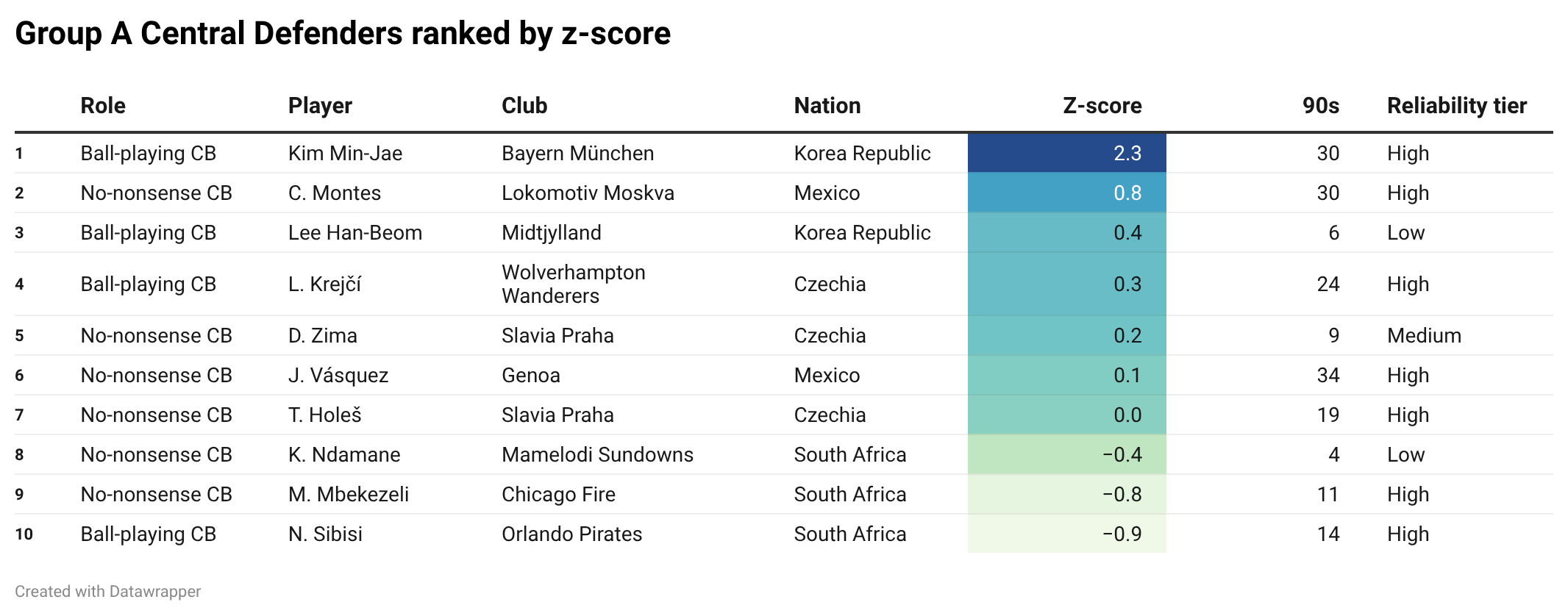
The Korea Republic centre-back comes out with a z-score of 2.3, which is ridiculous in this context.
Remember: a z-score of 2 means a player is two standard deviations above the average player in the sample. So, at least in this Group A pool, Kim is not just good. He is the standout central defender by a distance.
Second comes Mexico’s César Montes, with a z-score of 0.81. Not Kim-level, but still comfortably above average.
In third, we have another Korean defender, although with a lower-reliability sample, so I would be careful before over-interpreting that one. Then come two Czech defenders: Ladislav Krejčí and David Zima, one at Wolves, the other at Sparta Prague.
The first South African centre-backs only appear near the bottom of the table, both below the Group A average.
Which is interesting.
South Africa have the best goalkeeper in the group by this method, but some of the weakest centre-back scores.
What do I do with that?
3 — Best full-backs
Now to the full-backs.
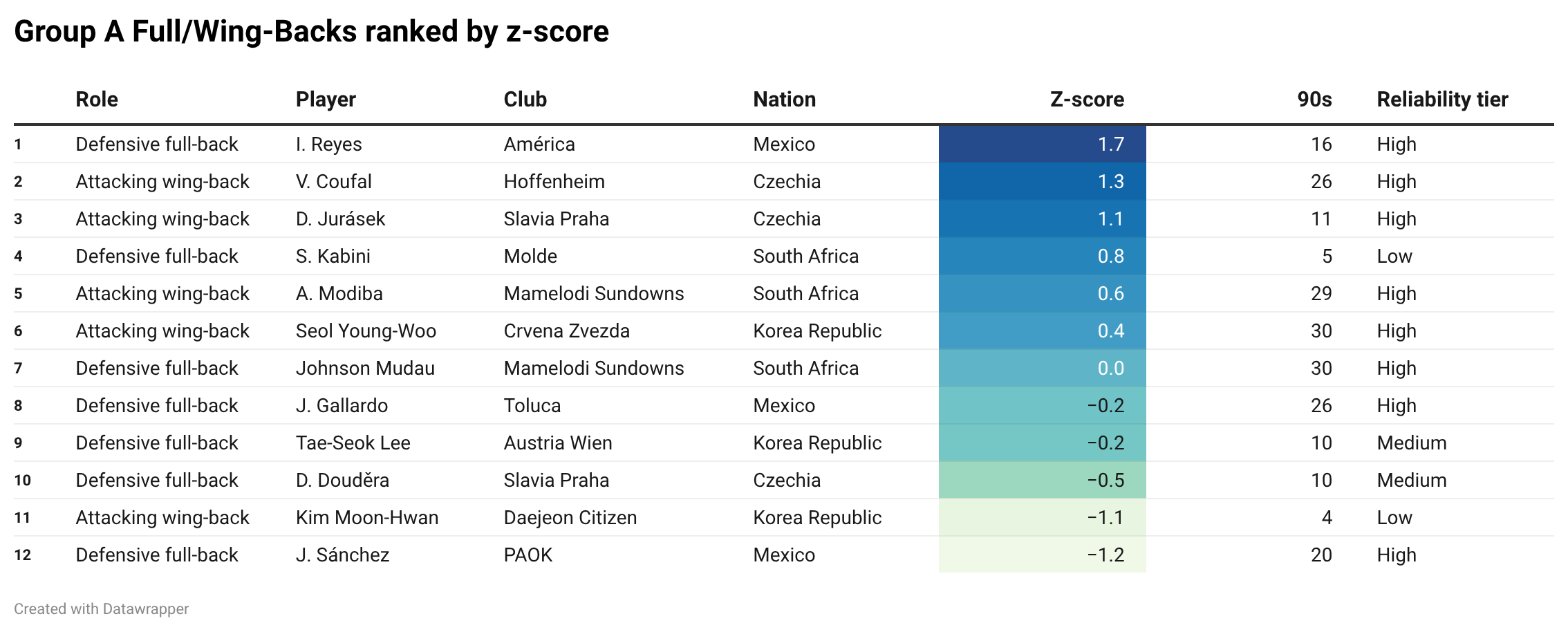
Here, Mexico’s Israel Reyes leads the way with a z-score of 1.68. Behind him, Czechia look very strong, with Vladimír Coufal and David Jurásek both above 1.0.
That feels like a genuine Czech strength: two flanks, two strong profiles, both coming out very well in the data.
Then we get two South African players — Siyabonga Kabini and Aubrey Modiba — also above the 0.5 mark. Again, anything above 0.5 is already a player meaningfully above the group average.
Interestingly, Korea Republic do not dominate this category. Only one Korean full-back comes out with a positive z-score.
Maybe their system does not favour full-backs. Maybe the role is less expressive in their national team. Maybe I should stop pretending I have watched enough Korea Republic full-back minutes to comment with confidence.
So I’ll stop there.
4 — Best midfielders
In midfield, we again have one clear standout. And once again, he is Korean.
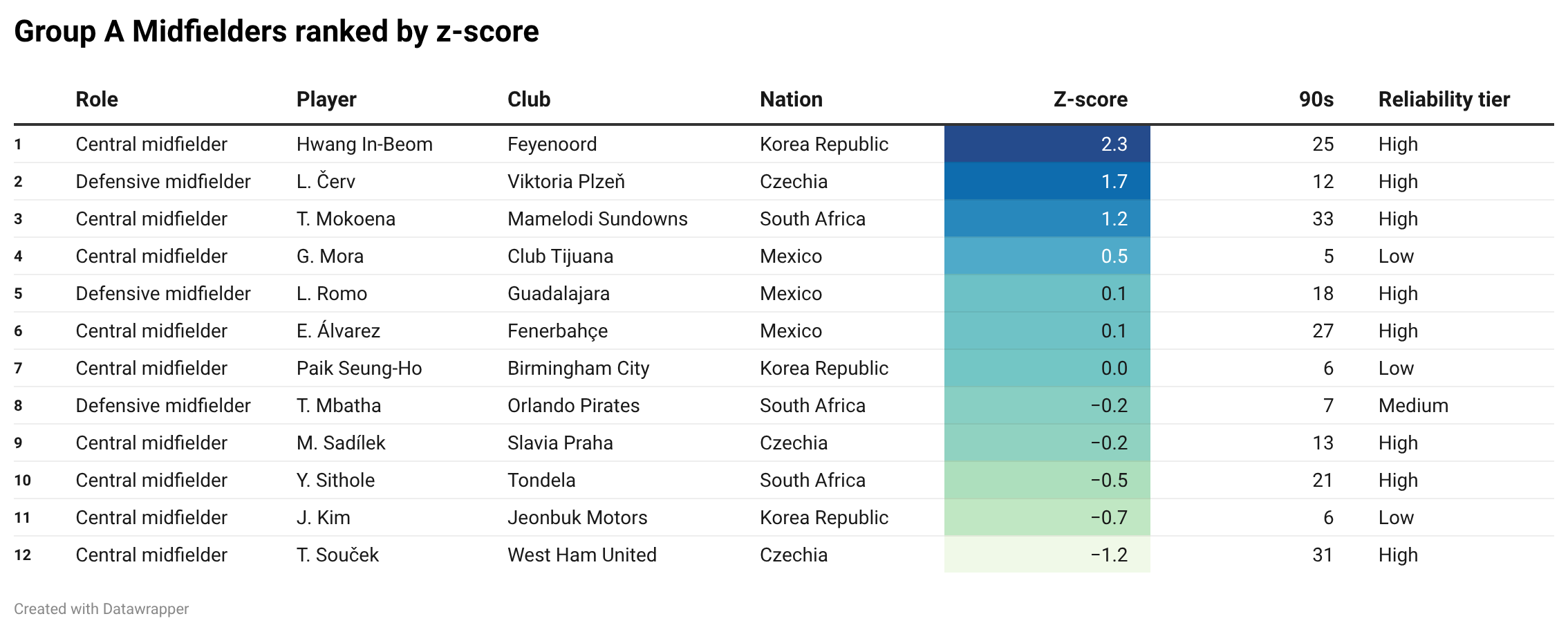
Hwang In-beom, now at Feyenoord, comes out with a z-score of 2.27. That is way, way above the sampled midfielders from Group A.
Second is Czechia’s Lukáš Červ, with 1.66. Third is South Africa’s Teboho Mokoena, from Mamelodi Sundowns, with 1.15.
So the top three midfielders are nicely spread: one Korean, one Czech, one South African.
Then things get interesting: the next three are all Mexican, although with lower scores.
So Korea have the standout player. Mexico kind of have depth. Czechia and South Africa each have one strong midfield profile.
Which is basically exactly the kind of sentence that makes me want to watch this group now.
5 — Best attacking midfielders
Among the attacking midfielders and wide attackers, Korea Republic take over.
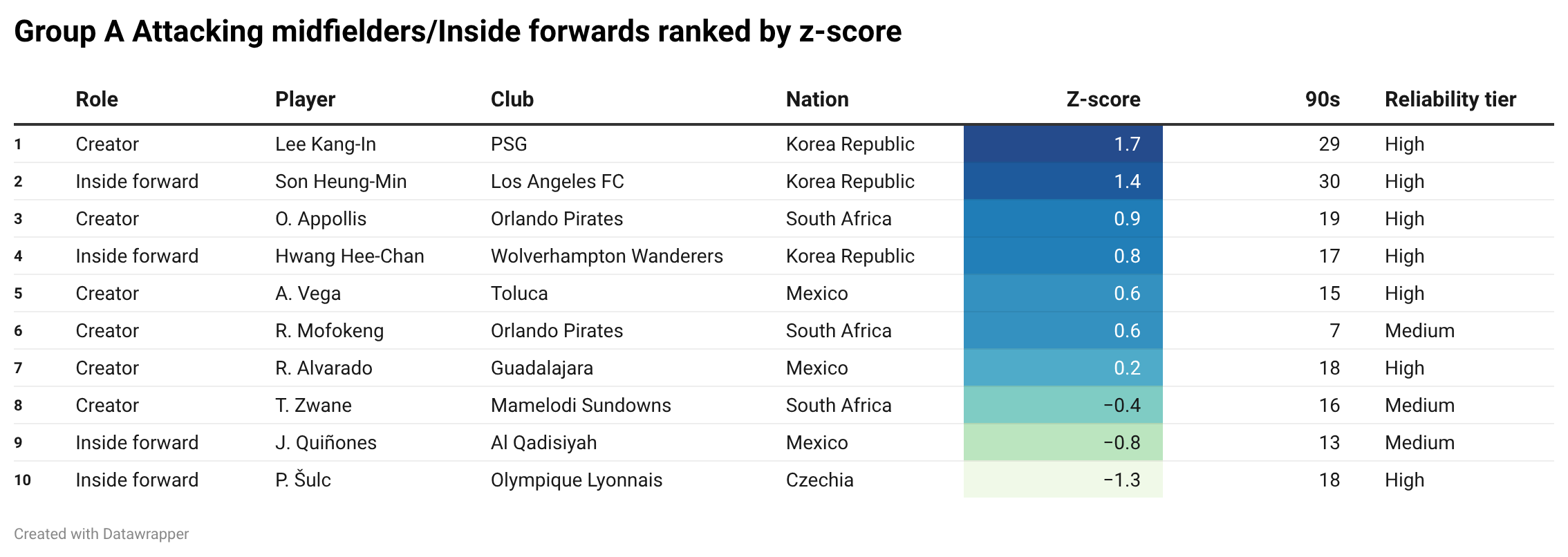
At the top we have Lee Kang-in (1.7), followed closely by Son Heung-min (1.4), and then Hwang Hee-chan (0.8) also appearing strongly. That is a serious attacking trio, and the data likes them a lot.
South Africa’s Oswin Appollis (0.9) also appears high, which is one of the more interesting names in the table. Mexico get a player into the top five too, but overall this category looks heavily Korean.
The striking thing is the Czech absence.
Czechia showed up strongly at full-back and reasonably well in defence and midfield. But in this attacking-mid / wide-attacker bucket, they do not really pop in the same way.
So, if we are doing this blindly, the attacking edge clearly belongs to Korea Republic.
6 — Best forwards
And finally, the cherry on top: the forwards.
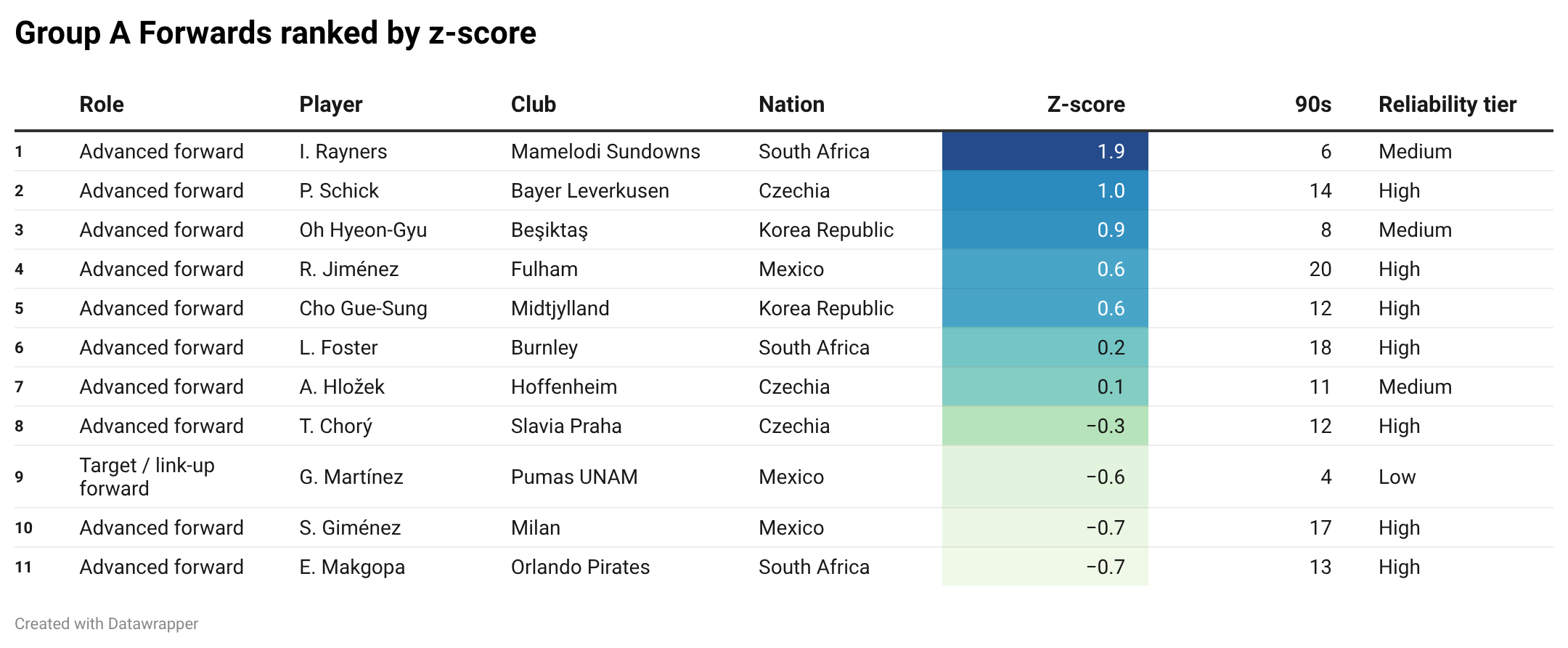
Here we have a player above everyone else: Iqraam Rayners (1.9), from Mamelodi Sundowns, who comes out almost two standard deviations above the average Group A forward. Had to google this one as well. Sorry.
That is a proper standout score, though.
Second comes Czechia’s Patrik Schick (1), which feels less surprising. Third is Korea Republic’s Oh Hyeon-gyu (0.9), now at Besiktas. Then comes Raúl Jiménez (0.6) in fourth.
I expected Jiménez to be a little higher, but hey. That is the whole point of doing this blind: sometimes the data pushes back against the names in your head.
South Africa have the standout. Czechia have the established name. Korea have a strong option. Mexico are still there, but not quite leading the line in the data.
So I am calling this category even.
So, what should we take from all this?
What should we take from all this amateur blind-data analysis?
First, Korea Republic look like the strongest team in the group on individual quality.
Not everywhere. But in the places that usually decide football matches — midfield and attack — they show up very strongly. Kim Min-jae dominates the centre-back table. Hwang In-beom dominates the midfield table. Lee Kang-in, Son Heung-min and Hwang Hee-chan dominate the attacking-mid / wide-attacker table. That is a pretty convincing spine.
Second, Czechia look solid in the less glamorous areas. They show well at full-back, have good centre-back options, a strong midfield profile in Červ, and of course Patrik Schick up front.
Third, South Africa are the most interesting team in the group. They have the best goalkeeper by the data, the standout striker in Rayners, and a strong midfield profile in Mokoena. But the centre-back scores are worrying. Best goalkeeper, weak central defenders. This is either a red flag, or the beginning of a very fun tournament story.
Fourth, Mexico do not really impress at the individual level in this blind-data exercise. That surprised me a bit. They have good players here and there — Israel Reyes, César Montes, a few midfielders, Jiménez still hanging around — but they do not dominate any category in the way Korea do. They look more like a team with decent depth than a team with obvious data standouts.
Maybe that is unfair. Maybe the model punishes them because they are hosts and played a different mix of games. Maybe tournament Mexico will do tournament Mexico things. But if I had to judge only from this exercise, I would not have Mexico as the automatic favourite.
Which means, naturally, Mexico will probably top the group and make me look stupid.
So here is the final blind-data prediction:
1. Korea Republic
2. Czechia
3. Mexico
4. South Africa
Let’s see whether the laptop knew ball.
Thank you for reading until the end ❤️
Cheers,
Martin